一、每门课程问题
用一条 SQL 语句查询 学生表每门课都大于 80 分的学生姓名。
解决办法一: having
思路:如果最小的课程都大于80分,那他所有的课程分数,肯定都大于80分!
代码实现
SELECT name
FROM student
GROUP BY name
HAVING MIN(score)> 80解决办法二:not in
可以用反向思维,先查询出表里面有小于 80 分的 name,然后用 not in 去除掉
代码实现
SELECT DISTINCT name
FROM student
WHERE name NOT IN
(SELECT DISTINCT name
FROM student
WHERE score <=80);二、topN 问题
准备:
create table `test1` (
`id` int(11) not null auto_increment,
`name` varchar(20) default null,
`course` varchar(20) default null,
`score` int(11) default null,
primary key (`id`)
) engine=innodb auto_increment=10 default charset=utf8
insert into test1(name,course,score)
values
('张三','语文',80),
('李四','语文',90),
('王五','语文',93),
('张三','数学',77),
('李四','数学',68),
('王五','数学',99),
('张三','英语',90),
('李四','英语',50),
('王五','英语',89);TOP 1
需求:查询每门课程分数最高的学生以及成绩
实现方法:可以通过自连接、子查询来实现。
a、自连接实现
select a.name,a.course,a.score
from test1 a join (select course,max(score) score from test1 group by course) b
on a.course=b.course and a.score=b.score;
b、子查询实现
select name,course,score
from test1 a
where score=(select max(score) from test1 where a.course=test1.course);
select name,course,score
from test1 a
where not exists(select 1 from test1 where a.course=test1.course and a.score < test1.score);TOP N
需求:查询每门课程前两名的学生以及成绩
实现方式:使用union all、自身左连接、子查询、用户变量等方式实现
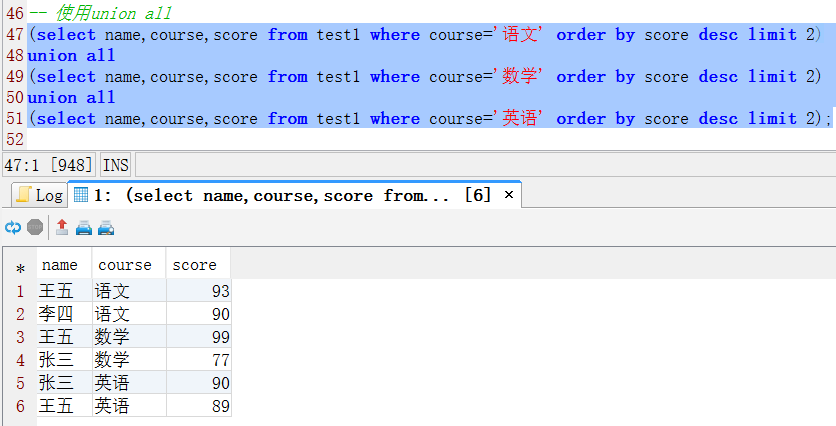
a、使用union all实现
(select name,course,score from test1 where course='语文' order by score desc limit 2)
union all
(select name,course,score from test1 where course='数学' order by score desc limit 2)
union all
(select name,course,score from test1 where course='英语' order by score desc limit 2);执行效果如下
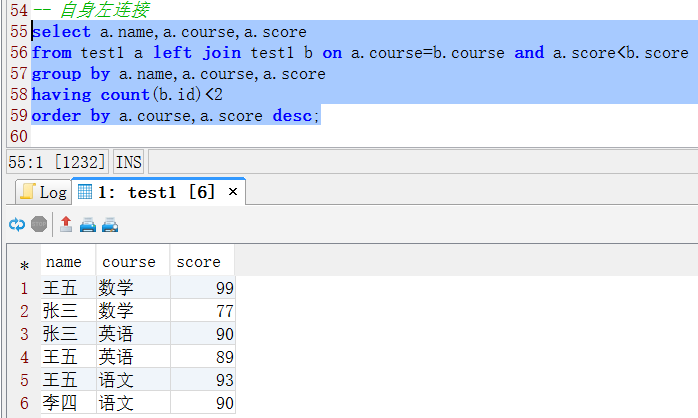
b、使用自身左连接
select a.name,a.course,a.score
from test1 a left join test1 b on a.course=b.course and a.score<b.score
group by a.name,a.course,a.score
having count(b.id)<2
order by a.course,a.score desc;执行效果如下
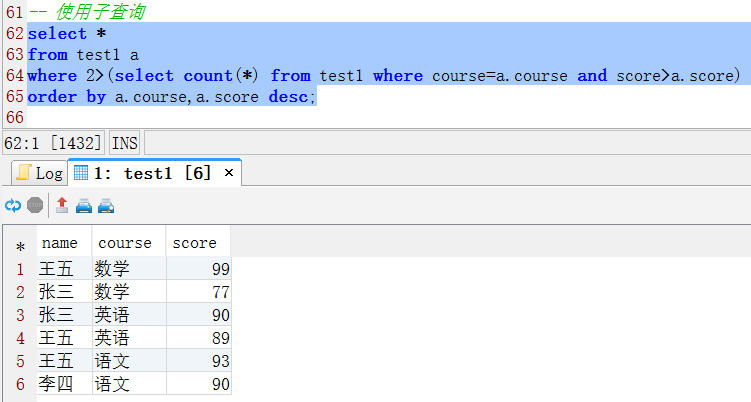
c、使用子查询
select *
from test1 a
where 2>(select count(*) from test1 where course=a.course and score>a.score)
order by a.course,a.score desc;执行效果如下
d、使用用户变量
set @num := 0, @course := '';
select name, course, score
from (
select name, course, score,
@num := if(@course = course, @num + 1, 1) as row_number,
@course := course as dummy
from test1
order by course, score desc
) as x where x.row_number <= 2;三、连续问题(7 天连续登陆)
准备:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for login_log
-- ----------------------------
DROP TABLE IF EXISTS `login_log`;
CREATE TABLE `login_log` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`stu_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`createtime` datetime(6) NULL DEFAULT CURRENT_TIMESTAMP(6),
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 20 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of login_log
-- ----------------------------
INSERT INTO `login_log` VALUES (1, 'zhangsan', '2021-03-07 09:58:29.438123');
INSERT INTO `login_log` VALUES (2, 'zhangsan', '2021-03-03 09:58:29.438123');
INSERT INTO `login_log` VALUES (3, 'zhangsan', '2021-03-05 09:58:29.438123');
INSERT INTO `login_log` VALUES (4, 'zhangsan', '2021-03-01 09:58:29.438123');
INSERT INTO `login_log` VALUES (5, 'lisi', '2021-02-04 09:58:29.438123');
INSERT INTO `login_log` VALUES (6, 'lisi', '2021-02-03 09:58:29.438123');
INSERT INTO `login_log` VALUES (7, 'lisi', '2021-02-02 09:58:29.438123');
INSERT INTO `login_log` VALUES (8, 'lisi', '2021-02-01 09:58:29.438123');
INSERT INTO `login_log` VALUES (9, 'lisi', '2021-02-05 09:58:29.438123');
INSERT INTO `login_log` VALUES (10, 'lisi', '2021-02-06 09:58:29.438123');
INSERT INTO `login_log` VALUES (11, 'lisi', '2021-02-07 09:58:29.438123');
INSERT INTO `login_log` VALUES (12, 'lisi', '2021-02-08 09:58:29.438123');
INSERT INTO `login_log` VALUES (13, 'xiaowang', '2021-02-05 09:58:29.438123');
INSERT INTO `login_log` VALUES (14, 'xiaoli', '2021-02-06 09:58:29.438123');
INSERT INTO `login_log` VALUES (15, 'xiaoli', '2021-02-07 09:58:29.438123');
INSERT INTO `login_log` VALUES (16, 'xiaozhao', '2021-02-08 09:58:29.438123');
INSERT INTO `login_log` VALUES (17, 'lisi', '2021-02-05 09:58:29.438123');
INSERT INTO `login_log` VALUES (18, 'xiaozhao', '2021-02-06 09:58:29.438123');
INSERT INTO `login_log` VALUES (19, 'lisi', '2021-02-07 09:58:29.438123');
SET FOREIGN_KEY_CHECKS = 1;实现思路:
1、因为每天用户登录次数可能不止一次,所以需要先将用户每天的登录日期去重。
2、再用row_number() over(partition by _ order by _)函数将用户id分组,按照登陆时间进行排序。
3、计算登录日期减去第二步骤得到的结果值,用户连续登陆情况下,每次相减的结果都相同。
4、按照id和日期分组并求和,筛选大于等于7的即为连续7天登陆的用户。
代码实现
-- 8.0版本:
-- 3 按照stu_name和日期分组并统计人数,筛选大于等于7的即为连续7天登陆的用户
select stu_name,count(num) num from
(
-- 2 计算登录日期,登录时间-用row_number() over(partition by _ order by _)函数将用户id分组的结果值
select stu_name,date(createtime)-row_number() over(partition by stu_name ORDER BY createtime) num from
(
-- 1、去重,每天多次登录,只保留一条
select distinct stu_name,DATE_FORMAT(createtime,'%Y-%m-%d')createtime from login_log
) t1
)t2 GROUP BY stu_name HAVING(count(1))>7
-- 5.7版本:
-- 声明用户变量,记录行号和登录用户名
set @row_number:=0,@customer_no:='';
-- 3 如果连续登录,date(createtime)-num 结果会相等
select stu_name,count( date(createtime)-num )as num from
(
-- 2 记录行号;
select @row_number:=
case
when @customer_no=l1.stu_name then @row_number+1
else 1
end as num,
@customer_no:= l1.stu_name stuName
,stu_name,DATE_FORMAT(createtime,'%Y-%m-%d') createtime from
(
-- 1 去除同一天登录多次
select DISTINCT stu_name,DATE_FORMAT(createtime,'%Y-%m-%d') createtime from login_log ORDER BY stu_name,createtime
) l1
) l2 GROUP BY l2.stu_name HAVING num>7
四、行转列问题
SQL行转列、列转行这个主题还是比较常见的,行转列主要适用于对数据作聚合统计,如统计某类目的商品在某个时间区间的销售情况。列转行问题同样也很常见。
行转列,就是在原来的数据集上减少行数,增加列的数量。具体是什么情况,大家请往下看。
这里有一张学生成绩表,注意看,小老王 2020 年的成绩缺失了。
name grade point
--------------- ------ --------
小老王 2019 3.6
小老王 2018 4.3
玛丽莲·梦露 2018 3.9
玛丽莲·梦露 2019 4.2
玛丽莲·梦露 2020 4.4
蒜你牛 2020 4.6
蒜你牛 2018 4.0
蒜你牛 2019 4.3 直接看表的数据不能很直观地了解在某个学年里每个学生的成绩,我们希望把每个学年拎出来作为列,就像下面这样子。
name 2018 2019 2020
--------------- ------ ------ --------
小老王 4.3 3.6 (NULL)
玛丽莲梦露 3.9 4.2 4.4
小李子 4.0 4.3 4.6 怎么拎出这几个列的数据呢?可以先试试用 case when 。把学年作为过滤的条件,比如过滤条件是 2018 的时候,只有属于该年度的成绩才能放到 2018 的列中。
SELECT
NAME,
CASE
WHEN grade = 2018
THEN POINT
END AS '2018',
CASE
WHEN grade = 2019
THEN POINT
END AS '2019',
CASE
WHEN grade = 2020
THEN POINT
END AS '2020'
FROM
t上面的 SQL 执行之后的结果如下:
name 2018 2019 2020
--------------- ------ ------ --------
小老王 (NULL) 3.6 (NULL)
小老王 4.3 (NULL) (NULL)
玛丽莲梦露 3.9 (NULL) (NULL)
玛丽莲梦露 (NULL) 4.2 (NULL)
玛丽莲梦露 (NULL) (NULL) 4.4
小李子 (NULL) (NULL) 4.6
小李子 4.0 (NULL) (NULL)
小李子 (NULL) 4.3 (NULL) 这个结果和我们想要的结果有点接近了,只是每个学生还出现在多行数据中,每个学生应该只对应一行数据才合理。
把多行的数据聚合成一行可以使用聚合函数,max()、min()、sum() 在这里都可以使用。因为我们要看到的是每个学生的成绩,所以要将 name 字段作为分组字段。完整的 SQL 如下:
SELECT
NAME,
MAX(
CASE
WHEN grade = 2018
THEN POINT
END) AS '2018',
MAX(
CASE
WHEN grade = 2019
THEN POINT
END) AS '2019',
MAX(
CASE
WHEN grade = 2020
THEN POINT
END) AS '2020'
FROM
t
GROUP BY NAME写行转列(不包括动态行转列)不难,关键得知道分析哪些字段要作为分组的依据,哪个字段将拆分成多个列。然后,套上下面这个模板就可以实现功能了。
SELECT
分组字段1,
分组字段2,
[ 分组字段n ],
MAX(
CASE
WHEN 条件1成立
THEN 数值对应的字段
END) AS '条件1的列名',
MAX(
CASE
WHEN 条件2成立
THEN 数值对应的字段
END) AS '条件2的列名',
MAX(条件判断n) AS '条件n的列名'
FROM
表
GROUP BY 分组字段1,
分组字段2,
[ 分组字段n ]五、留存问题
APP分析中经常用到AARRR模型(海盗模型)用来分析APP的现状,其中一个重要节点就是提高留存(Acquisition),而留存率这个指标在这个阶段可以说是核心指标也不为过。那如何用SQL计算留存率呢?
留存率指标中,通常需要关注次日留存、3日留存、7日留存和月留存。对新增用户而言,需要关注更细颗粒度的数据,也就是7日内每天的留存率。
留存率计算方法
假如今天新增了100名用户,第二天登陆了50名,则次日留存率为50/100=50%,第三天登录了30名,则第二日留存率为30/100=30%,以此类推。
用SQL的计算思路
- 用SQL调取出user_id和用户login_time的表,获得新增用户登录时间表。
- 根据user_id和login_time,增加一列first_day,此列存着每个用户最早登录时间。
- 有了最早登录时间和所有的登录时间,再增加一列by_day,这一列是用login_time - first_day ,得到0,1,2,3,4,5……,这就得到了某一天登录离第一次登录有多长时间。

获得一个这样的表
然后从表中提取数据,找到first_day对应的with_first列中0有多少个,1有多少个,一直到7以上。
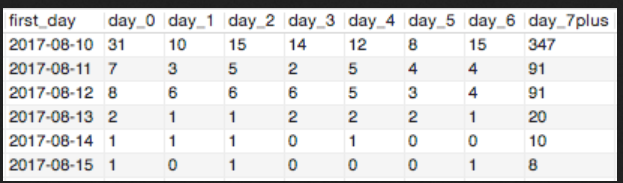
最后获得这个表
根据此表,就很容易计算出每天引流的留存率。
实际操作
数据:是我用excel随便模拟的数据,与真实情况不符。

模拟数据
数据库:MySQL
步骤一:从数据库中提取出user_id和login_time并排序
select
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
from user_info
group by 1,2;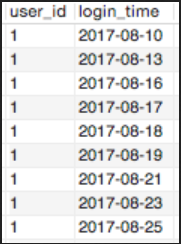
获得数据
步骤二:增加一列first_day,存储每个用户ID最早登录时间
SELECT
b.user_id,
b.login_time,
c.first_day
FROM
(select
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
from user_info
group by 1,2) b
LEFT JOIN
(SELECT ---找到user_id对应的最早登录时间,然后匹配带登录时间的user_id
user_id,
min(login_time) first_day
FROM
(select
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
from user_info
group by 1,2) a
group by 1) c
on b.user_id = c.user_id
order by 1,2;
得到first_day列
步骤三:用登录时间-最早登录时间得到一列by_day
SELECT
user_id,
login_time,
first_day,
DATEDIFF(login_time,first_day) as by_day
FROM
(SELECT
b.user_id,
b.login_time,
c.first_day
FROM
(SELECT
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
FROM user_info
GROUP BY 1,2) b
LEFT JOIN
(SELECT
user_id,
min(login_time) first_day
FROM
(select
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
from user_info
group by 1,2) a
group by 1) c
on b.user_id = c.user_id
order by 1,2) e
order by 1,2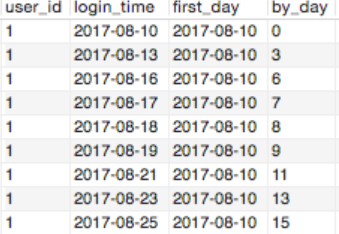
得到by_day
最后一步:提取字段作为列名
SELECT
first_day,
sum(case when by_day = 0 then 1 else 0 end) day_0,
sum(case when by_day = 1 then 1 else 0 end) day_1,
sum(case when by_day = 2 then 1 else 0 end) day_2,
sum(case when by_day = 3 then 1 else 0 end) day_3,
sum(case when by_day = 4 then 1 else 0 end) day_4,
sum(case when by_day = 5 then 1 else 0 end) day_5,
sum(case when by_day = 6 then 1 else 0 end) day_6,
sum(case when by_day >= 7 then 1 else 0 end) day_7plus
FROM
(SELECT
user_id,
login_time,
first_day,
DATEDIFF(login_time,first_day) as by_day
FROM
(SELECT
b.user_id,
b.login_time,
c.first_day
FROM
(SELECT
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
FROM user_info
GROUP BY 1,2) b
LEFT JOIN
(SELECT
user_id,
min(login_time) first_day
FROM
(select
user_id,
str_to_date(login_time,'%Y/%m/%d') login_time
FROM
user_info
group by 1,2) a
group by 1) c
on b.user_id = c.user_id
order by 1,2) e
order by 1,2) f
group by 1
order by 1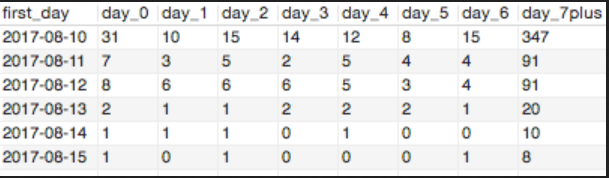
根据最后得到的数据,我们直接用除法或者加一个SQL语句,就能算出来留存率,之后的分析就是看自己了。



