2.Springboot集成Kafka
2.1依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.example</groupId>
<artifactId>java-learning</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<groupId>com.cll.spark</groupId>
<artifactId>kafka</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- Kafka客户端 -->
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
2.2 配置文件
spring:
application:
name: spring-boot-kafka
kafka:
bootstrap-servers: 127.0.0.1:90922.3 消费者消费策略
spring.kafka.consumer.auto-offset-reset选项
earliest:earliest策略时,如果 Kafka 消费者组没有找到有效的偏移量(offset)信息(例如是新的消费者组,或者之前提交的偏移量已过期、无效等),消费者会从分区的最早消息开始消费。也就是说,它会读取主题中所有已存在的消息,无论这些消息是什么时候产生的。
latest(默认):若采用latest 策略,在同样没有有效偏移量的情况下,消费者会从分区的最新消息开始消费。这意味着消费者会忽略在其开始消费之前就已经存在于分区中的消息,只处理从它开始消费时间点之后新产生的消息。
none:如果没有为消费者组找到以前的偏移量,则向消费者抛出异常
exception:spring-kafka不支持
默认情况下,启动一个新的消费者组时,会从每个分区的最新偏移量(该分区中最后一条消息的下一个位置)开始消费,如果希望从第一条消息开始消费,需要将消费者的auto.offset.reset=earliest;所以这里是读不到之前的hello,world,但是在该消费者启动后发送的消息可以被读取。
package com.cll.learning.kafka.a01;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class EventConsumer {
/**
* 默认从最新的消息读取,不接受历史消息
* @param message
*/
@KafkaListener(topics = {"test"}, groupId = "test-group")
public void onMessage(String message) {
System.out.println("receive message: " + message);
}
}
在配置后重启消费者发现仍然无法读取之前的消费者,是因为已经用相同的消费者组ID消费过该主题,并且Kafka保存了该消费者组的偏移量,即使设置了earliest,该设置也不会生效,因为kafka只会在找不到偏移量时使用这个配置。只需手动重置偏移量或者使用新的消费者组ID。
2.4 重置消费偏移量
重置偏移量需要将该消费者组关闭,这里重置到初始位置
./kafka-consumer-groups.bat --bootstrap-server 127.0.0.1:9092 --group test-group1 --topic test --reset-offsets --to-earliest --execute重启后,该消费者组将从分区的初始位置开始消费
2.5 生产者发送简单消息
package com.cll.learning.kafka.a01;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Component;
@Component
public class EventProducer {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendEvent() {
Message<String> message = MessageBuilder.withPayload("hello kafka")
.setHeader(KafkaHeaders.TOPIC, "test")
.build();
kafkaTemplate.send(message);
}
}测试
package com.cll.learning.kafka.a01;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
class EventProducerTest {
@Resource
private EventProducer eventProducer;
@Test
void sendEvent() {
eventProducer.sendEvent();
}
}2.6 发送ProducerRecord
public void sendEvent3() {
Headers headers = new RecordHeaders();
headers.add("key1", "value1".getBytes());
headers.add("key2", "value2".getBytes());
ProducerRecord<String, String> record = new ProducerRecord<>("test03", 0, "hello","kafka", headers);
kafkaTemplate.send(record);
}
2.7 发送默认消息
配置默认主题
kafka:
bootstrap-servers:
template:
default-topic: defaultTopic
consumer:
auto-offset-reset: latestpublic void sendEvent4() {
//默认topic
kafkaTemplate.sendDefault(0,System.currentTimeMillis(),"hello","kafka");
}2.8 阻塞式获取生产者消息发送结果
send和sendDefault发送消息返回的是CompleableFuture,表示异步操作结果的未来对象,可以避免发送者阻塞在发送这一步,同时可以确认服务器是否接收到消息
旧版本可能是使用CompletableFuture接收未来对象,新版本使用ListenableFuture
public void sendEvent4() throws ExecutionException, InterruptedException {
//默认topic
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.sendDefault(0, System.currentTimeMillis(), "hello", "kafka");
SendResult<String, String> sendResult = future.get();
if(sendResult.getRecordMetadata()!=null){
log.info("send success,{}",sendResult.getProducerRecord().value());
}
}2.9 非阻塞式获取生产者消息发送结果
public void sendEvent4() throws ExecutionException, InterruptedException {
//默认topic
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.sendDefault(0, System.currentTimeMillis(), "hello", "kafka");
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
// 消息发送成功的处理逻辑
System.out.println("Message sent successfully: " + result.getProducerRecord().value());
}
@Override
public void onFailure(Throwable ex) {
// 消息发送失败的处理逻辑
System.out.println("Message send failed: " + ex.getMessage());
}
});
}2.10发送对象消息
配置值序列化器,key序列化器也可以按需配置
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# key-serializer: 配置Jackson依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>代码
@Autowired
private KafkaTemplate<String, Object> objectKafkaTemplate;
public void sendEvent5() throws ExecutionException, InterruptedException {
objectKafkaTemplate.sendDefault(0, System.currentTimeMillis(), "user", new User("cll"));
}
2.11 Replica副本
为实现备份功能,保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且Kafka仍能够继续工作,Kafka提供副本机制,一个topic的每个分区都有1个或多个副本;
Replica副本分为Leader Replica和Follower Replica
Leader:每个分区多个副本中的主副本,生产者发送数据以及消费者消费数据,都是来自Leader副本
Follower:每个分区多个副本的从副本,实时从主副本中同步数据
当主副本发生故障时,某个从副本会成为新的主副本
副本个数不能为0,也不能大于节点个数
由于只有一个节点,每个分区只有一个副本,也就是主副本
./kafka-topics.sh --create --topic replicaTest --partitions 3 --replication-factor 1 --bootstrap-server 127.0.0.1:9092Java代码指定分区和副本,重新启动,该主题的已经存在的消息不会丢失
@Configuration
public class KafkaConfiguration {
@Bean
public NewTopic testTopic4(){
return new NewTopic("testTopic4", 2, (short) 1);
}
}重新修改,分区数量可以增加,不可以减少
2.12分区策略
Kafka为了增加系统的**伸缩性(Scalability)**,引入了分区(Partitioning)的概念。
Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。
通过这个设计,就可以以分区这个粒度进行数据读写操作,每个Broker的各个分区独立处理请求,进而实现负载均衡,提升了整体系统的吞吐量。
分区策略是决定生产者将消息发送到哪个分区的算法。
默认的分区器
org.apache.kafka.clients.producer.internals.DefaultPartitioner
创建消息时,根据你的参数决定发送到哪个分区:
指明partition的情况下,直 接将指明的值作为partition值; 例如partition=0,所有数据写入分区0;
没有指明partition值但有key的情况下,将key的hash值与topic的 partition数进行取余得到partition值;
例如:key1的hash值**=5, key2的hash值=6 ,topic的partition数=2,那 么key1 对应的value1写入1号分区,key2对应的value2写入**0号分区。既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直 使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进 行使用(如果还是0会继续随机)。
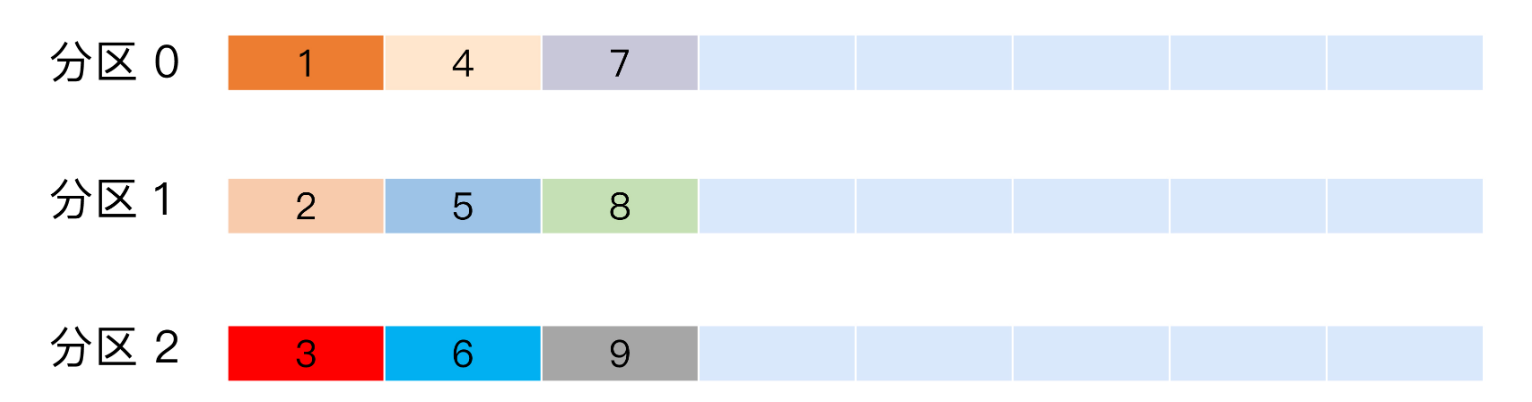
轮询策略
即按消息顺序进行分区顺序分配(比如图中消息顺序1,2,3,4…会按顺序分配在各个分区中)
随机策略
这是老版本Kafka的默认策略。
Key-ordering策略
有点类似哈希桶算法,对于有key的数据,用key的哈希值对分区数取模计算对应的分区。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();Kafka默认:
- 如果指定了 Key,那么默认实现按Key-ordering策略;
- 如果没有指定 Key,则使用轮询策略。
自定义分区策略:
Step1: 定义类实现 Partitioner 接口
Step2: 重写 partition()方法。
Step3: 设置partitioner.class。
@Component
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
String msgValues = value.toString();
int partition;
if (msgValues.contains("test")){
partition = 0;
}else {
partition = 1;
}
return partition;
}
@Override
public void close() {
//Nothing to close
}
@Override
public void configure(Map<String, ?> configs) {
}
}配置策略
public Map<String,Object> producerConfigs(){
Map<String,Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "14.103.244.88:9092");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.springframework.kafka.support.serializer.ToStringSerializer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class); //RoundRobinPartitioner,轮询策略
return props;
}
public ProducerFactory<String,Object> producerFactory(){
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String,Object> kafkaTemplate(){
return new KafkaTemplate<String,Object>(producerFactory());
}2.13通过@Payload和@Header接收消息
@KafkaListener(topics = {"test"}, groupId = "test-group2")
public void onMessage( @Payload String message, @Header(value = KafkaHeaders.OFFSET, required = false) String offset,@Header(value = KafkaHeaders.REPLY_PARTITION, required = false) String partition) {
// System.out.println(message);
log.info("message,{}", message);
log.info("partition,{}", partition);
log.info("offset,{}", offset);
}
2.14通过ConsumerRecord 接收消息
如果接收或者发送失败需要设置序列化信息
spring:
application:
name: spring-boot-kafka
kafka:
bootstrap-servers: 127.0.0.1:9092
template:
default-topic: defaultTopic
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# key-serializer:
consumer:
auto-offset-reset: latestConsumerRecord中包含很多的冗余信息
@KafkaListener(topics = {"test"}, groupId = "test-group2")
public void onMessage( ConsumerRecord<String, String> record) {
// System.out.println(message);
System.out.println(record);
}2.15对象消息
@KafkaListener(topics = {"${kafka.topic.name}"}, groupId = "test-group2")
public void onMessage( EventProducer.User record) {
// System.out.println(message);
log.info("user:{}",record);
}
2.16通过占位符指定消息主题
@KafkaListener(topics = {"${kafka.topic.name}"}, groupId = "test-group2")
public void onMessage( EventProducer.User record) {
// System.out.println(message);
log.info("user:{}",record);
}
2.17 监听器手动确认消息接收成功
kafka:
bootstrap-servers: 14.103.244.88:9092
template:
default-topic: defaultTopic
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# key-serializer:
consumer:
auto-offset-reset: latest
listener:
ack-mode: manual如果应用场景对消息的可靠性要求极高,不允许有任何消息丢失,且业务逻辑较为复杂,需要精细控制消息的处理和确认时机,那么手动确认是更好的选择。如果追求简单高效,对消息重复消费有一定的容忍度,且业务场景相对简单,自动确认则可以提高开发效率和消息处理速度。
@KafkaListener(topics = {"${kafka.topic.name}"}, groupId = "test-group2")
public void onMessage(EventProducer.User record, Acknowledgment acknowledgment) {
System.out.println(acknowledgment);
// System.out.println(message);
log.info("user:{}",record);
acknowledgment.acknowledge();
}如果没有确认的话就会造成消息重复消费,可以使用try catch处理
@KafkaListener(topics = {"${kafka.topic.name}"}, groupId = "test-group2")
public void onMessage(EventProducer.User record, Acknowledgment acknowledgment) {
try{
System.out.println(acknowledgment);
// System.out.println(message);
log.info("user:{}",record);
acknowledgment.acknowledge();
}catch (Exception e){
log.info("异常");
}
}
2.18指定分区和offset
首先创建一个含多个分区的主题
@Bean
public NewTopic testTopic4(){
return new NewTopic("test5", 5, (short) 1);
}
随机发送25个消息,Kafka默认分区策略会根据key的hash对分区数取模
public void sendEvent5() throws ExecutionException, InterruptedException {
for (int i = 0; i < 25; i++) {
User user = new User("cll"+i);
kafkaTemplate.send("test5","k"+i,user);
}
} @KafkaListener(groupId = "test5",topicPartitions = {
@TopicPartition(topic = "${kafka.topic.name}",
partitions = {"0", "1", "2"},
partitionOffsets = {
@PartitionOffset(partition = "3", initialOffset = "3"),
@PartitionOffset(partition = "4", initialOffset = "3")
}
)
})
public void onMessage(EventProducer.User record, Acknowledgment acknowledgment) {
try {
System.out.println(acknowledgment);
// System.out.println(message);
log.info("user:{}", record);
acknowledgment.acknowledge();
} catch (Exception e) {
log.info("异常");
}
}
对于分区1,2,3的策略是earliest,只会消费一次,再次重启后不会重复消费。对于分区4,5而言每次重启都会从offset 3开始消费。
批量消费消息
spring:
application:
name: spring-boot-kafka
kafka:
bootstrap-servers: 14.103.244.88:9092
template:
default-topic: defaultTopic
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# key-serializer:
consumer:
auto-offset-reset: earliest
max-poll-records: 2
listener:
type: BATCH
ack-mode: manual
消费消息,每次消费两条
@KafkaListener(groupId = "test6",topics = "test6")
public void onMessage2(List<ConsumerRecord<String, Object>> records,Acknowledgment acknowledgment) {
System.out.println("======================");
try {
records.forEach(record -> {
System.out.println(record);
});
// System.out.println(acknowledgment);
// System.out.println(message);
// log.info("user:{}", record);
acknowledgment.acknowledge();
} catch (Exception e) {
log.info("异常");
}
}2.19 消费消息拦截器
拦截器
package com.cll.learning.kafka.a01.config;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import java.util.Map;
@Slf4j
public class CustomConsumerInterceptor implements ConsumerInterceptor<String,String> {
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
@Override
public ConsumerRecords onConsume(ConsumerRecords records) {
log.info("消息消费之前:{}",records);
return records;
}
@Override
public void onCommit(Map offsets) {
log.info("消费者提交偏移量之后调用:{}",offsets);
}
}Spring本身提供消费者工厂和监听器工厂,但是无法配置拦截器,需要自定义消费者工厂和监听器配置并在@KafkaListener指定自定义监听器工厂,要注意消费者和生产者的反序列化器和序列化器要保持一致
package com.cll.learning.kafka.a01.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConsumerConfig {
public Map<String,Object> consumerConfigs(){
Map<String,Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.springframework.kafka.support.serializer.JsonDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.springframework.kafka.support.serializer.JsonDeserializer");
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomConsumerInterceptor.class.getName());
return props;
}
@Bean
public ConsumerFactory<String,String> customConsumerFactory(){
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public KafkaListenerContainerFactory customKafkaListenerContainerFactory(ConsumerFactory<String,String> customConsumerFactory)
{
ConcurrentKafkaListenerContainerFactory<String,String> listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>();
listenerContainerFactory.setConsumerFactory(customConsumerFactory);
return listenerContainerFactory;
}
}指定监听器工厂
@KafkaListener(groupId = "test6",topics = "test6",containerFactory = "customKafkaListenerContainerFactory")
public void onMessage2(List<String> records) {
System.out.println("======================");
try {
records.forEach(record -> {
System.out.println(record);
});
} catch (Exception e) {
log.info("异常");
}
}2.20 消费者转发消息
@KafkaListener(groupId = "test6",topics = "testFrom",containerFactory = "customKafkaListenerContainerFactory")
@SendTo(value = "testTo")
public Object onMessage2(ConsumerRecord<String,Object> record) {
System.out.println("======================");
try {
System.out.println(record);
} catch (Exception e) {
log.info("异常");
}
return record.value() + "---forward";
// return null;
}
@KafkaListener(groupId = "test7",topics = "testTo")
public void onMessage3(ConsumerRecord<String,Object> record) {
System.out.println("=========转发=============");
try {
System.out.println(record);
} catch (Exception e) {
log.info("异常");
}
}
需要给监听器设置replyTemplate
@Configuration
public class KafkaConsumerConfig {
public Map<String,Object> consumerConfigs(){
Map<String,Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "14.103.244.88:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.springframework.kafka.support.serializer.JsonDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.springframework.kafka.support.serializer.JsonDeserializer");
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomConsumerInterceptor.class.getName());
return props;
}
@Bean
public ConsumerFactory<String,String> customConsumerFactory(){
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public KafkaListenerContainerFactory customKafkaListenerContainerFactory(ConsumerFactory<String,String> customConsumerFactory,KafkaTemplate<String, String> replyTemplate)
{
ConcurrentKafkaListenerContainerFactory<String,String> listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>();
listenerContainerFactory.setConsumerFactory(customConsumerFactory);
listenerContainerFactory.setReplyTemplate(replyTemplate);
return listenerContainerFactory;
}
@Bean
public KafkaTemplate<String, String> replyTemplate(
ProducerFactory<String, String> producerFactory) {
return new KafkaTemplate<>(producerFactory);
}
}2.21 消费者消费消息时的分区策略
设置主题中哪些分区由哪些消费者消费
RangeAssignor
10个分区,三个消费者
0,1,2,3 消费者1
4,5,6 消费者2
7,8,9 消费者3
原理:RangeAssignor 基于每个主题进行分区分配。对于每个主题,它会将可用分区按数字顺序排列,将消费者按成员 ID 的字典序排列。然后,用分区数量除以消费者数量,确定每个消费者应分配的分区数。如果不能整除,靠前的消费者会多分配一个分区。
分配示例:假设有 2 个消费者 C0 和 C1,2 个主题 T0 和 T1,每个主题有 3 个分区,分别为 T0P0、T0P1、T0P2、T1P0、T1P1、T1P2。按照 RangeAssignor 策略,分配结果为 C0:(T0P0, T0P1, T1P0, T1P1),C1:(T0P2, T1P2)。
适用场景:当需要对两个主题数据进行分区连接时,使用 RangeAssignor 比较合适,因为它能使相同分区的数据在一个消费者上进行消费,便于进行关联操作。
局限性:如果消费者消费多个主题且不需要进行连接操作,使用 RangeAssignor 可能导致数据倾斜。因为对于每个主题,靠前的消费者总会获取更多分区,可能使这些消费者处理的数据量远大于其他消费者,从而影响性能。
在 Kafka 的消费者组中,当出现组成员数量变化、订阅主题数量变化、订阅主题的分区数变化等情况时,会触发 Rebalance(重平衡)过程。在 Leader 选举完成后,Leader 会根据 RangeAssignor 算法来分配消费方案,决定哪个消费者负责消费哪些主题的哪些分区。
public void sendEvent5() throws ExecutionException, InterruptedException {
for (int i = 0; i < 100; i++) {
SendResult<String, Object> test5 = kafkaTemplate.send("test8", String.valueOf(i), "haha"+i).get();
System.out.println(test5.getRecordMetadata().partition());
}
}消费者
@KafkaListener(groupId = "test6",topics = "test8",concurrency = "3")
public Object onMessage2(ConsumerRecord<String,Object> record) {
System.out.println("======================");
try {
System.out.println(Thread.currentThread().getId()+""+record);
} catch (Exception e) {
log.info("异常");
}
return null;
// return null;
}
RoundAssignor
比如10个分区,三个消费者
0,3,6,9 消费者1
1,4,7 消费者2
2,5,8 消费者3
消费者
package com.cll.learning.kafka.a01.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.RoundRobinAssignor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.ui.Model;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConsumerConfig {
public Map<String,Object> consumerConfigs(){
Map<String,Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "14.103.244.88:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.springframework.kafka.support.serializer.JsonDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.springframework.kafka.support.serializer.JsonDeserializer");
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomConsumerInterceptor.class.getName());
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName());
return props;
}
@Bean
public ConsumerFactory<String,String> customConsumerFactory(){
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public KafkaListenerContainerFactory customKafkaListenerContainerFactory(ConsumerFactory<String,String> customConsumerFactory)
{
ConcurrentKafkaListenerContainerFactory<String,String> listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>();
listenerContainerFactory.setConsumerFactory(customConsumerFactory);
return listenerContainerFactory;
}
}


